Batch computation¶
Copyright (c) 2024 QuAIR team. All Rights Reserved.
This tutorial involves how to use batch computation to simplify a series of inputs in QuAIRKit.
Table of Contents
[1]:
import torch
import quairkit as qkit
from quairkit import Circuit
from quairkit.database import *
from quairkit.loss import ExpecVal, Measure
qkit.set_dtype("complex128")
Batch computation in quantum circuit¶
Circuit class in QuAIRKit supports add batched parameters and gates to the circuit.
For parameterized gates like \(R_x(\theta)\), \(R_y(\theta)\), \(R_z(\theta)\), one can add batched parameters to the circuit by passing a 3-dimensional tensor to gate function, where the 3 dimensions are:
len(qubits_idx) : the number of qubits acted by the gates;
batch_size : the number of batched parameters;
num_acted_param : the number of parameters that characterize the gate. For example, num_acted_param for Ry gate is 1 and that for universal three qubit gate is 15.
Here is an example of batched parameters as an input onto a parameterized quantum circuit.
[2]:
num_qubits = 2
batch_size = 3
list_x = torch.rand(num_qubits * batch_size * 1) # num_acted_param=1
cir = Circuit(num_qubits)
cir.rx(param=list_x) # set Rx gate
print(f"Quantum circuit output: {cir()}")
# this is equivalent to below code
# list_x = list_x.view(num_qubits, batch_size, 1).permute([1, 0, 2])
# for param in list_x:
# cir_1 = Circuit(num_qubits)
# cir_1.rx(param=param)
# print(f"Quantum circuit output for adding one Rx gate: {cir_1()}")
Quantum circuit output:
-----------------------------------------------------
Backend: default-pure
System dimension: [2, 2]
System sequence: [0, 1]
Batch size: [3]
# 0:
[ 0.94+0.j 0. -0.33j 0. -0.11j -0.04-0.j ]
# 1:
[ 0.93+0.j 0. -0.3j 0. -0.23j -0.07-0.j ]
# 2:
[ 0.92+0.j 0. -0.38j 0. -0.11j -0.04-0.j ]
-----------------------------------------------------
For oracles stored as torch.Tensor, one can add batched matrices to the circuit by oracle.
[3]:
cir_ora = Circuit(2)
list_unitary = random_unitary(1, size=batch_size)
print(f"The shape of oracle unitary: {list_unitary.shape}")
cir_ora.oracle(list_unitary, [1])
print(f"Quantum circuit output: {cir_ora()}")
# this is equivalent to below code
# for idx, unitary in enumerate(list_unitary):
# cir_ora2 = Circuit(2)
# cir_ora2.oracle(unitary, [1])
# print(f"Quantum circuit {idx}: {cir_ora2()}")
The shape of oracle unitary: torch.Size([3, 2, 2])
Quantum circuit output:
-----------------------------------------------------
Backend: default-pure
System dimension: [2, 2]
System sequence: [0, 1]
Batch size: [3]
# 0:
[-0.47+0.38j 0.28+0.75j -0. +0.j 0. +0.j ]
# 1:
[-0.67-0.41j 0.17+0.59j 0. -0.j 0. +0.j ]
# 2:
[ 0.42+0.35j -0.28-0.79j 0. +0.j 0. -0.j ]
-----------------------------------------------------
QuAIRKit also supports batched channels through batching their Kraus or Choi operators. One can add batched channels to the circuit via kraus_channel or choi_channel. Notice that Kraus representation is recommended in batch computation.
[4]:
cir_kra = Circuit(2)
list_kraus = random_channel(num_qubits=1, size=batch_size)
cir_kra.kraus_channel(list_kraus, [0])
print(f"Kraus channel: {cir_kra()}")
output_state = cir_kra()
# this is equivalent to below code
# for idx, kraus in enumerate(list_kraus):
# cir_kra2 = Circuit(2)
# cir_kra2.kraus_channel(kraus, [0])
# print(f"Kraus channel {idx}: {cir_kra2()}")
Kraus channel:
-----------------------------------------------------
Backend: default-mixed
System dimension: [2, 2]
System sequence: [0, 1]
Batch size: [3]
# 0:
[[0.91+0.j 0. +0.j 0.16+0.23j 0. +0.j ]
[0. +0.j 0. +0.j 0. +0.j 0. +0.j ]
[0.16-0.23j 0. +0.j 0.09+0.j 0. +0.j ]
[0. +0.j 0. +0.j 0. +0.j 0. +0.j ]]
# 1:
[[ 0.3 +0.j 0. +0.j -0.08+0.45j -0. +0.j ]
[ 0. +0.j 0. +0.j -0. +0.j -0. +0.j ]
[-0.08-0.45j 0. -0.j 0.7 +0.j 0. +0.j ]
[ 0. -0.j 0. -0.j 0. +0.j 0. +0.j ]]
# 2:
[[ 0.69+0.j 0. +0.j -0.07-0.46j 0. -0.j ]
[ 0. +0.j 0. +0.j 0. -0.j 0. -0.j ]
[-0.07+0.46j -0. +0.j 0.31+0.j 0. +0.j ]
[-0. +0.j -0. +0.j 0. +0.j 0. +0.j ]]
-----------------------------------------------------
[5]:
cir_cho = Circuit(2)
list_choi = random_channel(num_qubits=1, target="choi", size=batch_size)
cir_cho.choi_channel(list_choi, [1])
print(f"Choi channel: {cir_cho()}")
# this is equivalent to below code
# for idx, choi in enumerate(list_choi):
# cir_cho2 = Circuit(2)
# cir_cho2.choi_channel(choi, [0])
# print(f"Choi channel {idx}: {cir_cho2()}")
Choi channel:
-----------------------------------------------------
Backend: default-mixed
System dimension: [2, 2]
System sequence: [0, 1]
Batch size: [3]
# 0:
[[ 0.13+0.j -0.22-0.26j 0. +0.j 0. -0.j ]
[-0.22+0.26j 0.87+0.j -0. +0.j 0. +0.j ]
[ 0. +0.j 0. -0.j 0. +0.j 0. -0.j ]
[-0. +0.j 0. +0.j -0. +0.j 0. +0.j ]]
# 1:
[[0.15+0.j 0.07+0.35j 0. +0.j 0. +0.j ]
[0.07-0.35j 0.85+0.j 0. +0.j 0. +0.j ]
[0. +0.j 0. +0.j 0. +0.j 0. +0.j ]
[0. +0.j 0. +0.j 0. +0.j 0. +0.j ]]
# 2:
[[0.26+0.j 0.17+0.4j 0. +0.j 0. +0.j ]
[0.17-0.4j 0.74+0.j 0. +0.j 0. +0.j ]
[0. +0.j 0. +0.j 0. +0.j 0. +0.j ]
[0. +0.j 0. +0.j 0. +0.j 0. +0.j ]]
-----------------------------------------------------
Mathematical property of Kraus operators is checked.
One can then check that this circuit preserves the trace.
[6]:
tr = output_state.trace()
torch.allclose(tr, torch.ones_like(tr))
[6]:
True
For clarity, the following figure illustrates how batch computation works in quantum circuits.
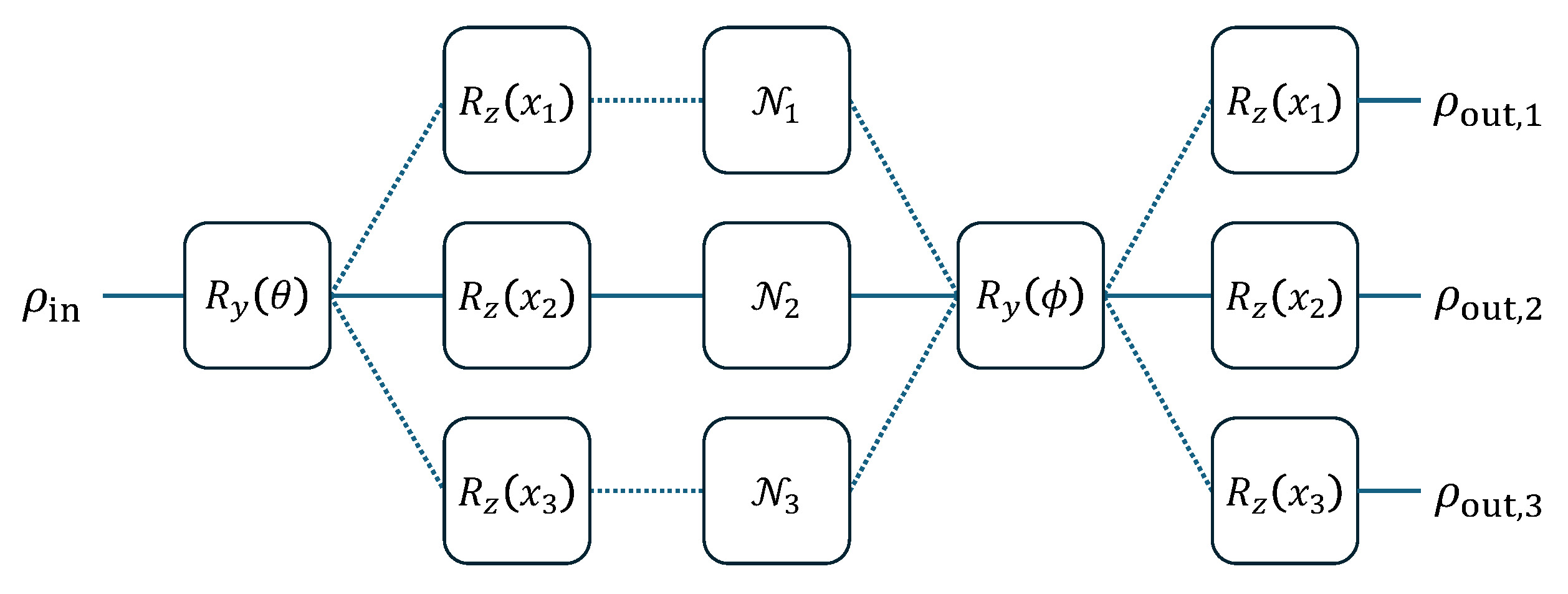
Fig.1: Depiction of batched quantum circuits on single input state.
The code of these circuits is given as follows
[7]:
rho = random_state(1)
list_x = torch.rand(batch_size)
list_depo = torch.stack(
[depolarizing_kraus(torch.rand(1)) for _ in list(range(batch_size))]
)
batch_cir = Circuit(1)
batch_cir.ry()
batch_cir.rz(param=list_x)
batch_cir.kraus_channel(list_depo, 0)
batch_cir.ry()
batch_cir.rz(param=list_x)
print(f"Output state: {batch_cir(rho)}")
Output state:
-----------------------------------------------------
Backend: default-mixed
System dimension: [2]
System sequence: [0]
Batch size: [3]
# 0:
[[ 0.51+0.j -0.05+0.02j]
[-0.05-0.02j 0.49-0.j ]]
# 1:
[[ 0.52+0.j -0.07-0.j]
[-0.07+0.j 0.48+0.j]]
# 2:
[[ 0.52-0.j -0.06+0.j]
[-0.06-0.j 0.48+0.j]]
-----------------------------------------------------
Batch computation in measurement¶
Measurement in QuAIRKit also support batch computation. We start with an observable represented by Hamiltonian and a projection valued measure (PVM).
[8]:
H = random_hamiltonian_generator(num_qubits)
print(f"Hamiltonian: {H.pauli_str}")
Hamiltonian: [[-0.6382438933999832, 'Z0,Y1'], [0.06489214850001601, 'Y0,X1'], [0.18022556176418747, 'Y0']]
One can call the expec_val of State class, or implement the neural network module ExpecVal on batched states.
[9]:
print(f"Output state: {output_state}")
op = ExpecVal(H)
print(f"expectation value: {op(output_state)}")
# this is equivalent to below code
# for state in output_state:
# print(f"expectation value of each: {op(state)}")
print(f"expectation value: {output_state.expec_val(H)}")
# return the expectation value of each Pauli term
print(
f"expectation value of each Pauli term:\n{output_state.expec_val(H, decompose=True)}"
)
Output state:
-----------------------------------------------------
Backend: default-mixed
System dimension: [2, 2]
System sequence: [0, 1]
Batch size: [3]
# 0:
[[0.91+0.j 0. +0.j 0.16+0.23j 0. +0.j ]
[0. +0.j 0. +0.j 0. +0.j 0. +0.j ]
[0.16-0.23j 0. +0.j 0.09+0.j 0. +0.j ]
[0. +0.j 0. +0.j 0. +0.j 0. +0.j ]]
# 1:
[[ 0.3 +0.j 0. +0.j -0.08+0.45j -0. +0.j ]
[ 0. +0.j 0. +0.j -0. +0.j -0. +0.j ]
[-0.08-0.45j 0. -0.j 0.7 +0.j 0. +0.j ]
[ 0. -0.j 0. -0.j 0. +0.j 0. +0.j ]]
# 2:
[[ 0.69+0.j 0. +0.j -0.07-0.46j 0. -0.j ]
[ 0. +0.j 0. +0.j 0. -0.j 0. -0.j ]
[-0.07+0.46j -0. +0.j 0.31+0.j 0. +0.j ]
[-0. +0.j -0. +0.j 0. +0.j 0. +0.j ]]
-----------------------------------------------------
expectation value: tensor([-0.0832, -0.1626, 0.1648])
expectation value: tensor([-0.0832, -0.1626, 0.1648])
expectation value of each Pauli term:
tensor([[-0.0000, -0.0000, -0.0000],
[ 0.0000, 0.0000, 0.0000],
[-0.0832, -0.1626, 0.1648]])
Similarly, to measure the output state, one can call the measure of State class, or implement the neural network module Measure on batched states. The following code measures the second qubit of the output state.
[10]:
output_state = cir_kra()
basis = random_unitary(1).unsqueeze(-1)
pvm = basis @ basis.mH
print(f"The shape of PVM: {pvm.shape}")
op = Measure(pvm)
print(f"expectation value: {op(output_state, [0])}")
# this is equivalent to below code
# for state in output_state:
# print(f"expectation value: {op(state, [0])}")
print(f"expectation value: {output_state.measure([0], measure_op=pvm)}")
The shape of PVM: torch.Size([2, 2, 2])
expectation value: tensor([[0.8531, 0.1469],
[0.2781, 0.7219],
[0.5958, 0.4042]])
expectation value: tensor([[0.8531, 0.1469],
[0.2781, 0.7219],
[0.5958, 0.4042]])
One can also keep the collapsed states after the measurement by setting keep_state = True.
Table: A reference of notation conventions in this tutorial.
Symbol |
Variant |
Description |
|---|---|---|
\(R_{x/y/z}(\theta)\) |
rotation gates about the \(X\)/\(Y\)/\(Z\)-axis |
|
\(\rho_{\text{in}}\) |
input quantum state |
|
\(\rho_{\text{out}}\) |
\(\rho_{\text{out},1}\), \(\rho_{\text{out},2}\), \(\rho_{\text{out},3}\) |
output quantum state |
\(\mathcal{N}\) |
\(\mathcal{N}_1\), \(\mathcal{N}_2\), \(\mathcal{N}_3\) |
quantum channel |
[11]:
qkit.print_info()
---------VERSION---------
quairkit: 0.5.1
torch: 2.11.0+cu130
torch cuda: 13.0
numpy: 2.2.6
scipy: 1.15.3
matplotlib: 3.10.5
---------SYSTEM---------
Python version: 3.10.18
OS: Linux
OS version: #1 SMP PREEMPT_DYNAMIC Thu Jun 5 18:30:46 UTC 2025
---------DEVICE---------
CPU: 13th Gen Intel(R) Core(TM) i9-13980HX
GPU: (0) NVIDIA GeForce RTX 4090 Laptop GPU